Fl studio Speech Synthesizer
Данная статья является частью цикла статей «Fl Studio»
Синтезатор речи обрабатывает текст, чтобы создать компьютеризованный либо похожий на обработанный вокодером вокал для ваших проектов. Пресеты, имеющие расширение *.SPEECH поддерживаются всеми родными для FL Studio плагинами, которые используют пользовательские сэмплы для синтезирования, к примеру: Sampler, Granulizer, Fruity Slicer и Fruity Scratcher.
Содержание
Как открыть синтезатор речи [ править ]
Синтезатор речи не является отдельным инструментом и поэтому не появляется в списке добавления плагинов, это всплывающее диалоговое окно, которое преобразует текст в звук, а затем делает результат в виде нарезанных звуковых клипов. Для добавления речевых сэмплов в проект есть два основных метода:
- Перетащите речевой пресет из папки Speech окна браузера на пустой инструмент (или плагин, который принимает .wav файлы). Откроется диалоговое окно настроек, измените текст по своему вкусу, а затем нажмите кнопку OK, чтобы применить пресет к инструменту.
- Щёлкните правой кнопкой мыши по речевому пресету в папке Speech окна браузера и выберите либо Open in new Fruity Slicer channel либо Open in new Slicex channel. После изменения речи по своему вкусу в окне Speech properties, плагин даст вам возможность воспроизведения.
Диалог свойств речи [ править ]
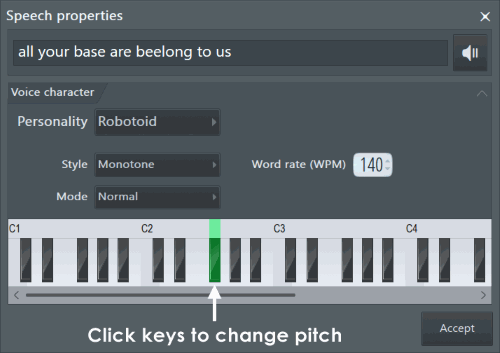
- Text (текст)
- Speech Text box (текстовое поле речи) – введите здесь текст, который будет синтезирован программой.
- Listen button (кнопка прослушивания) – нажмите для прослушки сэмпла на основе текущих параметров.
- Voice (голос)
- Personality combo box (меню выбора личности) – нажмите на это меню, чтобы выбрать голос личности. Личность меняется тембр используемого голоса. Они отличаются тембрами используемого голоса. Остальные голосовые настройки также устанавливаются в значения по умолчанию для выбранной личности.
- Style combo box (меню выбора стиля) – выбор стиля для интонации голоса. Режимы Monotone/Sing (пение/монотонное) используют постоянную тональность для всех слов. Natural (натуральный) напоминает естественную интонацию речи. Random (случайный) использует случайную тональность для каждого слова.
- Mode (режим) – выберите количество шума смешиваемого с генерируемым голосом. Normal (нормальный) использует естественный уровень шумов в голосе. Breathy (придыхание) использует больше шума, чтобы создать «придыхание» голоса. Whispered (шепот) для синтеза речи использует только шум, создавая тем самым эффект «шепчущего» голоса.
- Rate LCD (экран скорости) – устанавливает скорость голоса.
- Pitch Semitone combo box (меню выбора тональности в полутонах) – выбор тональности голоса в полутонах.
- Pitch Octave LCD (экран тональности в октавах) – выбор тональности голоса в октавах.
- Accept button (кнопка применить) – применяет речевой пресет к выбранному генератору/эффекту. Если вы изменили некоторые настройки в этом диалоговом окне вам будет предложено сохранить настроенный пресет с новым названием.
Редактирование синтезируемой речи [ править ]
- Сдвиг тональности для отдельных слов — вы можете установить параметры сдвига тональности и затухания для каждого отдельного слова во фразе. Для этого вам нужно всего лишь поместить значение сдвига (в полутонах) после слова в виде числа в круглых скобках: На полтона вверх (1), 2 на два полутона вниз (-2). Если в этом примере базовый, указанный в настройках сдвиг тональности равен F#2, то слову up будет назначен сдвиг, равный G2 (на полтона выше), а слову down сдвиг тональности, равный E2 (на два полутона ниже).
- Разделение слов — для получения более естественного звучания предложений вы можете попробовать заменить пробелы « » на знаки подчеркивания «_». Таким образом, фраза: This is example sentence превращается в This_is_example_sentence.
- Обратите внимание, что фразы с подчеркиванием будут распознаны инструментом Fruity Slicer как одно слово и не будут нарезаны должным образом (см. ниже).
Поддержка Fruity Slicer [ править ]
При открытии пресета речевого файла в одном из инструментов Fruity Slicer, каждое слово фразы автоматически нарезается так, что каждое слово находится в отдельном куске. Благодаря этой функции, файл BeatSlicer grid (*.zgr) автоматически создаёт инструмент Fruity Slicer, который содержит предложения.
Источник
Синтезаторы речи для «продвинутых»
Каждый из нас, наверняка сталкивался тем или иным образом с синтезатором речи. В общем и целом их называют «преобразователями из текста в речь» или, более распространённая аббревиатура – TTS (Text-to-speech). Сейчас любой желающий может зайти в переводчик Google и услышать собственными ушами, как работают подобные системы. Было время когда эту технологию активно внедряли в различные системы перевода. Но нас, как музыкантов, интересует использование синтезаторов речи в качестве вокала, при создании музыки, а также в виде плагина для нашей рабочей станции. И это тоже возможно – рассмотрим несколько подобных VST-инструментов и программ.
Aques Tone 2
Первый плагин – от японских разработчиков, со всеми вытекающими последствиями (рис.1).
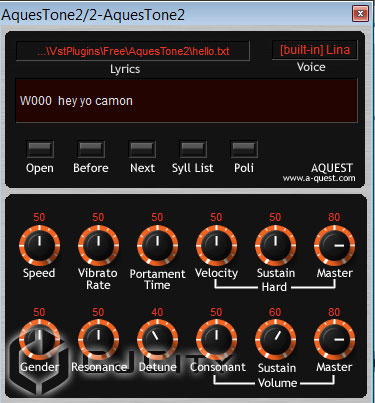
Рисунок 1. Интерфейс Aques Tone 2.
Неизвестно, заведомо ли японцы решили привнести некоторые ошибки, вроде «Poli» вместо «Poly», но и других японских «фишек» здесь хватает. Например, руководство пользователя доступно только на японском. Но это полбеды. Плагин заточен в основном под японские фонемы! Чтобы понять это на практике представьте, как японец произнёс бы английскую фразу, записанную в японской транскрипции.
Кроме того, органов управления не так уж и много. Основная секция здесь в верхнем окне, в котором загружается файл с нужными фразами. Почему нельзя было сделать возможность писать фразы и проигрывать их «на лету» — непонятно. Ну что ж, попробуем синтезировать какую-нибудь фразу.
Для этого нужно в любом текстовом редакторе написать её, сохранить, а затем загрузить в плагин. Возьмём, к примеру, простую фразу «Hey, yo, come on»! Для того, чтобы Aques Tone 2 распознал её более-менее адекватно, нужно написать так: «hey yo camon». И сохранить файл с расширением txt (в моём случае – hello.txt).
Теперь открываем этот файл, нажав на кнопку Open (рис. 2). Не забываем установить тип файлов «txt».
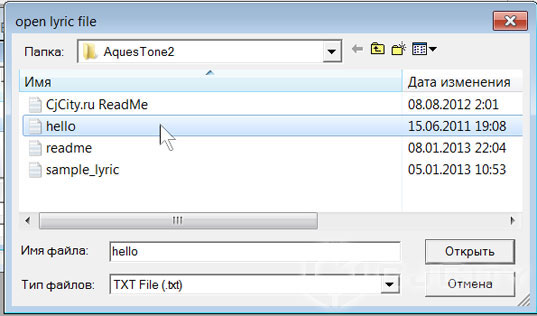
Рисунок 2. Открываем файл с «лирикой».
Если всё правильно загрузилось, в нашем основном окне, мы увидим записанную нами фразу – «hey yo camon».
Следующий шаг – прописать партию. Собственно, обозначить моменты, когда будет звучать каждый слог. Схема здесь такая – с нажатием каждой новой ноты проигрывается очередной слог. На рисунке 3 я подписал над каждой нотой за какой слог она отвечает.
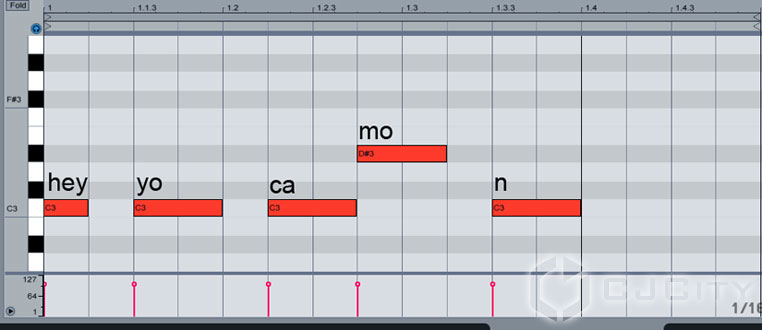
Рисунок 3. Прописываем ноты для слогов.
Как видим, располагаются они своим особым образом. К примеру, почему-то звук «N» отделился на отдельную ноту, а не «прилип» к слогу «MO». Да и вообще, если послушать демо-фразы, встроенные в программу, то очевидно прослушивается направленность на японский язык.
Регуляторы, представленные в этом vst-инструменте, не представляют особого интереса. Они отвечают за некоторые характеристики эмулируемого голоса. Самым ощущаемым на слух я выделил бы Gender. Он делает голос либо более «мужским», либо более «женским». Кавычки я поставил не случайно, т.к. однозначно сложно сказать – мужской ли это голос, либо женский. Также, к примеру, регулятор Resonance при очень низких значениях делает голос совершенно неестественным, а при высоких – более мягким. Остальные параметры можно «крутить» на свой вкус. Ну и напоследок хочется отметить, что доступен всего лишь один встроенный голос под именем «Lina». Впрочем, послушайте сами сэмпл из нескольких тактов созданной нами фразы – сделайте выводы. Плагин бесплатный.
VirSyn Cantor 2
В отличие от предыдущего представителя, Cantor 2 представляет собой более «продвинутую» систему для синтезирования вокальных партий, но уже за денежку. Он также имеет версию в виде отдельной программы. Хотя и vst-инструмент представляет собой аналог piano-roll в секвенсоре: взгляните на интерфейс (рис. 4).
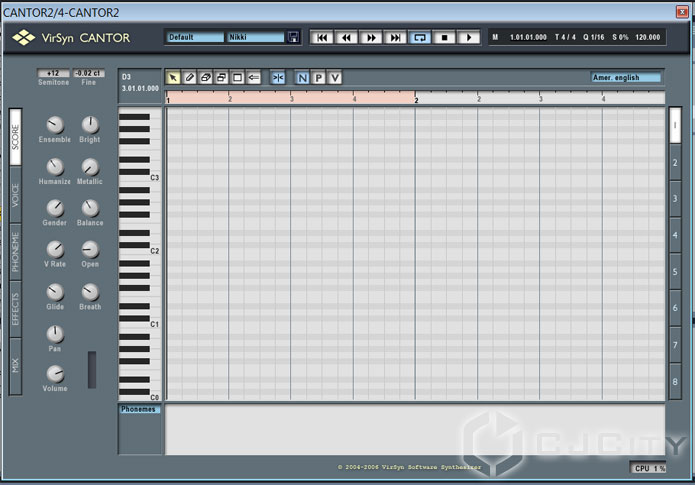
Рисунок 4. Главное окно VirSyn Cantor.
Поскольку этот плагин обладает большим инструментарием, он может манипулировать большим количеством параметров голоса. Но начинать нужно всё равно с построения фразы по слогам. Как несложно догадаться, делается это посредством piano roll. Здесь же есть панель инструментов с привычными «карандашами», «ластиками» и т.п. Собственно, попробуем синтезировать упоминавшуюся выше фразу «hey, yo, come on»! Нарисуем события в виде прямоугольных областей, а также подпишем каждый из них, как на рисунке 5.
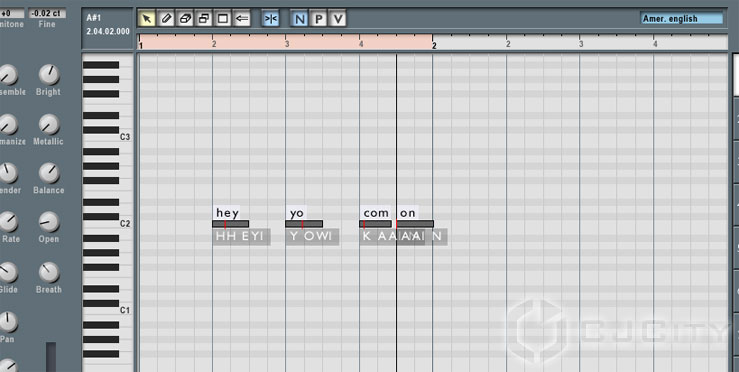
Рисунок 5. «Рисуем» фразу в piano-roll в Cantor.
Как можно увидеть, слова написаны над событиями не все целиком. Например, слово «come on» разбито на два слога – «com» и «on». Внимательные пользователи заметят, что внизу автоматически прописаны фонемы – это довольно удобная функция. Если вдаваться в подробности и нюансы, то нужно очень хорошо представлять себе, что такое фонемы и прочие тонкие нюансы звучания речи, доступные разве что узким специалистам. Мы просто оставим это как есть и посмотрим как оно работает в общем. Но это не всё. Теперь в самой миди-партии дорожки Cantor 2 тоже нужно прописать партию, соответственно которой будут звучать наши слова (слоги). Сделаем так, как на рисунке 6.
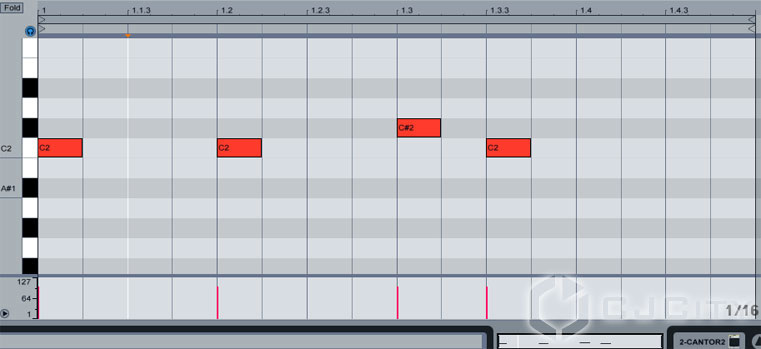
Рисунок 6. «Рисуем» фразу в piano-roll в секвенсоре.
Теперь можно включить проигрывание в секвенсоре и убедиться, что у нас появился некий звук на выходе.
Далее настроим некоторые нюансы звучания. Сразу оговорюсь, что для исследования всех нюансов настройки Cantor 2 нужно писать целую книгу. В рамках этой статьи мы рассмотрим общие параметры. Итак, во-первых, можно выбрать уже готовый голос. Доступно их около десятка. Открыть их можно в верхней части программы, в опции Load voice (рис. 7).
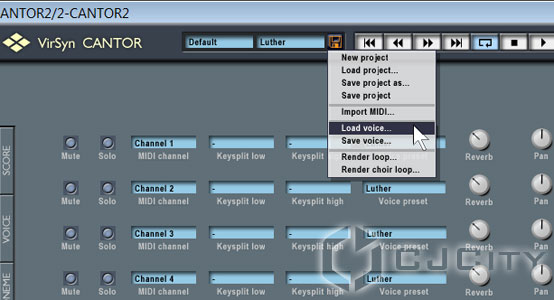
Рисунок 7. Загружаем голос.
По-умолчанию был установлен «Nikki», но я переставил его на «Luther». Можете попробовать различные голоса, как женские, так и мужские.
Во-вторых, здесь есть секция эффектов (собственно, раздел Effects, рис. 8).
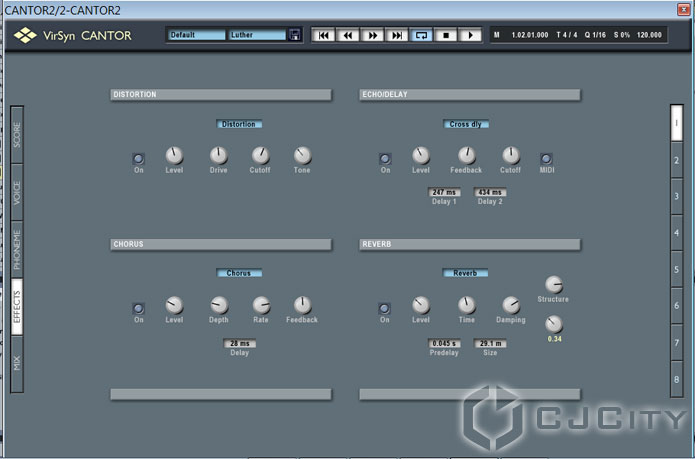
Рисунок 8. Добавляем эффекты.
Доступно 4 эффекта – Distortion, Echodelay, Chorus и Reverb. Хотя эти же эффекты можно добавлять и отдельно.
Про секции Phoneme и Voice нет смысла рассказывать, т.к. они довольно сложны в освоении и разобраться в их настройках может разве что довольно узкий специалист. Хотя никто не мешает покрутить ручки в этих секциях и таким образом изменить звучание. Либо корпеть над теорией синтезирования речи, а также над руководством пользователя Cantor, чтобы понимать как это всё должно работать. В общем, довольно много параметров, довольно сложно и довольно примитивный звук получается в итоге.
Тем не менее, даже новичок, если постарается, сможет получить звучание, наподобие того, что получилось у меня.
Fruity Loops Studio
Возможно, многие из вас, увидев Fruity Loops, удивятся, каким образом он попал в эту статью, ведь это скорее, программа для создания музыки, нежели синтезатор речи. Всё дело в том, что Fruity Loops имеет в своём арсенале очень неплохой синтезатор речи. Называется он Speech Synthesizer. И хоть его нет в виде отдельного плагина, но можно вставить сам FL как vst-плагин в вашу рабочую станцию и там уже использовать его Speech Synthesizer. Но я всё же предпочитаю создавать речевую партию в самом FL, затем экспортировать её в аудиофайл, после чего использовать в любой рабочей станции.
Итак, попробуем создать партию из предыдущего примера непосредственно в FL Studio. Вставим этот плагин в наш проект (рис.9).
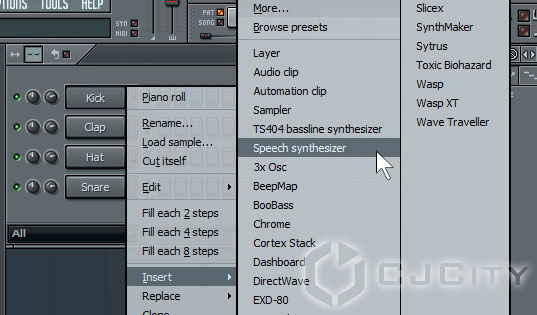
Рисунок 9. Добавляем Speech Synthesizer в Fruity Loops.
Как только мы добавим его в проект, автоматически появится окно, предлагающее ввести наш текст. Можно долго не думать и сразу ввести нашу фразу из примеров выше (рис. 10).
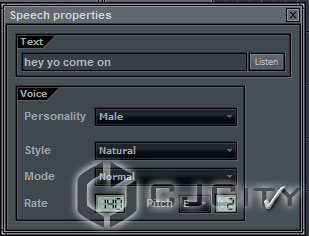
Рисунок 10. Настройки параметров речи.
Кроме того, можно сразу же установить и другие параметры речи, такие как голос (доступно около 20 голосов), стиль произношения, режим (шёпотом, с придыханием, либо обычный) и настройки темпа и тональности. Советую сразу настроить темп (у меня он, допустим 140, соответственно темпу проекта). Кнопка Listen позволяет прослушать партию «на лету», до её создания. После того, как мы подобрали нужные параметры нажимаем галочку, программа предложит нам сохранить наш файл с созданной речевой партией и в проекте создаётся новая партия с вокалом (рис. 11).
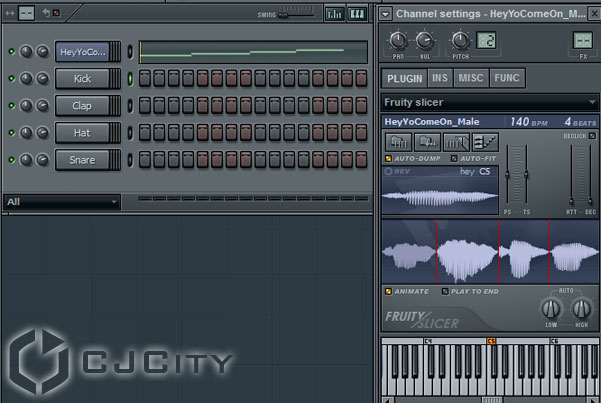
Рисунок 11. Новая речевая партия в проекте.
Нам не нужно заморачиваться – Speech Synthesizer создал за нас дорожку, которая представляет собой Fruity Slicer с созданной в нём партией, разбитой по нотам, где каждому слову соответствует отдельная нота (на рисунке 11 справа как раз видно, что у нас есть партия с 4 кусочками). Кроме того, в piano roll созданы дорожки для нот с подписанными словами, что очень удобно (рис. 12).
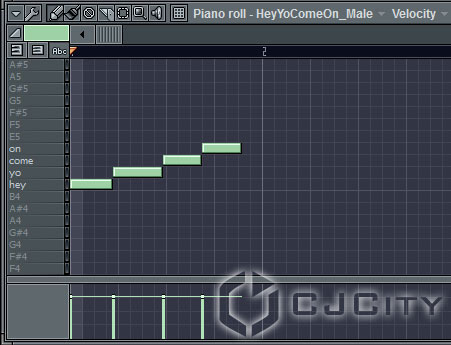
Рисунок 12. Окно piano-roll с новой партией.
Всё довольно наглядно и просто. Не нужно прописывать фонемы, подбирать слоги, чтобы фраза звучала правильно. Достаточно просто ввести фразу – она будет звучать уже довольно сносно и разборчиво. Затем также просто можно переставлять слова и экспортировать партию в желаемый аудиоформат. Можно убедиться самим, прослушав пример.
Что же лучше из рассмотренных синтезаторов речи?
Лично моё мнение: лучше живая речь, живой вокал. Если же выбирать из вышеупомянутых программ, то, безусловно по количеству настроек и параметров выигрывает Cantor 2. Тем более, что он претендует на звание не просто синтезатора речи, а даже вокального синтезатора. Если выбирать по удобству, простоте и качеству звучания, я отдаю предпочтение Speech Synthesizer из Fruity loops.
Дополнение от редакции
Есть ещё бесплатная программа для синтезирования речи — AnalogX SayIt. Можно настроить различные параметры и после предпрослушки сгенерировать результат в звуковой файл.
Источник